Pretty early, for congress standards I guess, hit the CCL around 11 AM and most floors and assemblies were empty, which had its own vibe.
Some people I wanted to meet during the congress I tried to meet today and was quite successful with.
By accident, I ran into a pitch of „| age“ a tool „a simple file encryption tool & format“, which looked quite cool and will try to play with it at a later point.
For many years I wanted to go to a CCC and this year because of different reasons I was finally able to go, this blog post is going to cover my planning and following posts will hopefully follow.
Preparing
There is a log of coverage already how to prepare for a congress. Obviously, you need a ticket. I got my ticket thanks to a co-worker who is a pretty active member of a local chaos group, so was fairly easy (thx stean)
So after getting a ticket, a place to stay needs to be found. In most cases, I run with AirBnB, this time I was unable to find a cosy place nearby so I ended up doing a hotel reservation and I hope this was a good choice.
And last but not least, transportation. The way to go here for me is using german railway services, Deutsche Bahn. There is even a special page from Deutsche Bahn to get a special ticket for a lower price.
Stuff
Of course, going to a conference you need your basic stuff as for every conference/travel, so I will not go into that too much. Especially for the congress, I tagged most of my gear that I plan to bring to the venue with my twitter handle and my domain so that it is easy to find the owner.
In addition to my normal list I packed the following items:
permanent markers (white/black) – maybe I can help with those
There will be water dispensers on #36C3 again, so please bring a bottle to minimize use of one-way plastic bottles. Of course you can also reuse a normal plastic bottle.
Please also note that tap water is drinkable in Germany (and usually tastes good).
The tech also needs some extra time, in particular, updating every service/application running is critical. As I do not trust the wifi (as with any other wifi) VPN and a backup VPN was tested/updated.
To be able to work on stuff I also freed up some space on the devices, just in case.
Power up batteries, external power supplies and co. I do not want to run out of power.
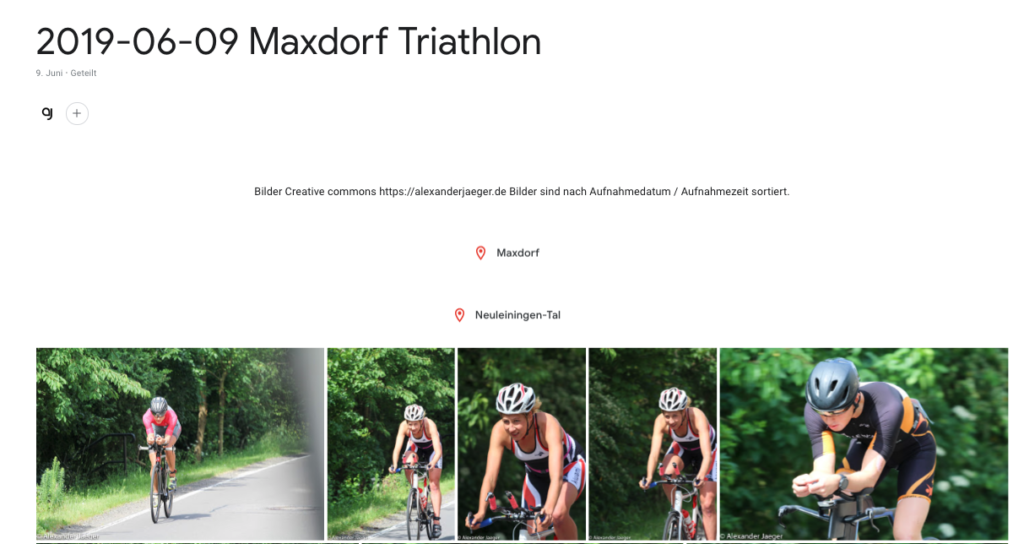
Auch wenn ich leider nicht am Triathlon in Maxdorf teilnehmen konnte (irgendwann schaffe ich es mal an die Startlinie) haben wir das perfekte Wetter genutzt für einen kleinen Ausflug an die Radstrecke dieses top organisierten Wettkampfes, ich habe die Kamera ausgepackt und wir haben gute zwei Stunden die Radler angefeuert.
Aus eigener Erfahrung weiß ich, wie positiv selbst einzelne Anfeuerungen am Rand helfen. Und auch richtig cool wieviele Athleten sich für den Zuspruch bedankt und mit uns gelacht haben.
Da ich mir nicht sicher bin, ob es einen Foto Service gab, bzw, ich mit den Fotos nichts verdienen will, habe ich einfach alle ohne Aussortieren hochgeladen.
Die Bilder dürfen zur eigenen Verwendung unter CC-BY-SA genutzt werden unter der Nennung von Alexander Jäger als Fotograf und über einen Link hier her freue ich mich immer.
The idea of that series is to cover an API each month, provide some samples, talk about potential target audience and use cases for the API.
Service description
The first API to be covered is apility. The service is marketed as „Minimal and Simple Anti-Abuse API for Everyone.“ and the web page starts with a Google-like search mask.
apility screenshot
API documentation
The API documentation is pretty comprehensive and available via web page: https://apility.io/apidocs/. The documentation also gives nice curl examples for every API endpoint that can be copy-pasted.
apility APi documentation
API pricing
The API itself is free but is limited in regards to API calls that can be done. pricing options are available on https://apility.io/pricing/
Example
As an example I tried to get ratings for IPs / domains for a recent APT OSINT report.
To get started you need to sign up and verify your account via an email that you receive shortly after signing up.
import requests from configparser import ConfigParser
config = ConfigParser() config.read("config.cfg") APIKEy = config.get('API', 'APIKEY') print(APIKEy) url = "https://api.apility.net/baddomain/" headers = { 'accept': "application/json", 'x-auth-token': APIKEy } f = open('./input.txt', 'r') for line in f.readlines(): print("Will investigate "+line) response = requests.request("GET", url+line, headers=headers, verify=False) print(response.text) print("finished")
It should be noted that there is also a python package available at https://github.com/Apilityio/python-cli and can be installed (but I have not tested it) via:
pip install apilityio-cli
or
easy_install apilityio-cli
Target audience
The target audience for the API as well as the service is:
sysadmins who want to use the offered data to sharpen perimeter security tools
Researchers to add more data points to their research
Threat Intelligence professionals as a data source
Incident responders to monitor if any of the ASN / domains they are responsible for is added to one of the blacklists
Cyber security is a global issue but most people interested in the topic are not able to visit the big conferences because they are expensive or because they are not allowed to travel to the destinations.
But thanks to the evolving technology of video hosting sites and the fact that capturing talks on video is more and more getting the new norm, a lot of good security talks can be watched online.
Looking for good videos, I ended up in either a total mess of crappy videos or pretty good videos where not pushed up on the result pages by video hosting platforms because low number of views (most security talks at the moment to not attract that much audience). This is when I started a new repository called: „awesome security videos„
The idea is simple, collect and curate a list of online videos that is good from a content and a presentation point of view.
Because it is on github, I hope for others to contribute ideas, I will also have a close look on twitter, so feel free to send me a DM to https://twitter.com/alexanderjaeger
While writing some code, I stumbled across a API documentation, that only had curl examples (prefer to have curl examples over no examples at all) but I had some troubles converting it to proper python code and a friend recommended a page called: https://curl.trillworks.com/
Today, FoxIT published an blog post with an github repository listing potential CobaltStrike servers for the last few years.
I was interested in the data so I processed the data with my osint-timesketch scripts to add passiveDNS and passiveSSL data. I only took the IPs that where last seen >2019 to not create to much data.
Adding it to timesketch was pretty straight forward:
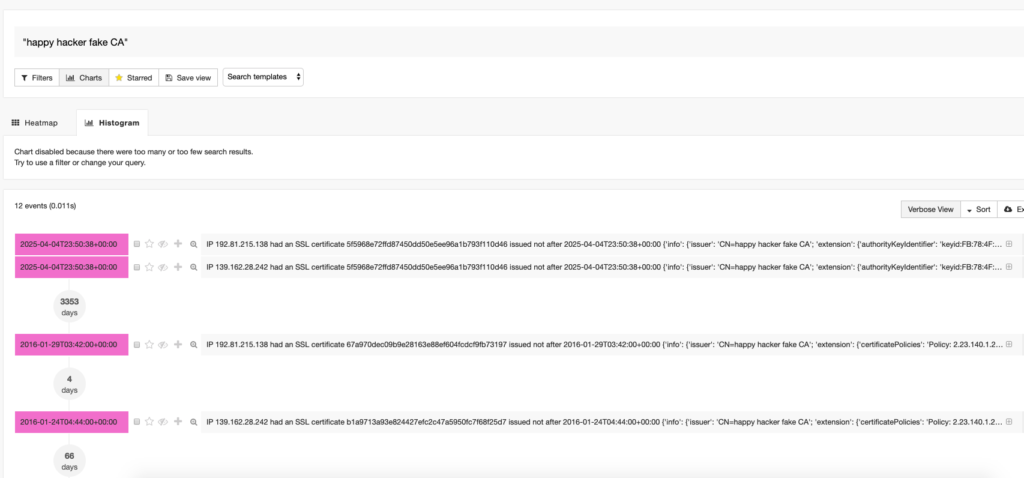
Some quick findings, after searching for google I discovered several weird certificates, among them.
Some weird things: safebrowsing(.)net is not owned by google, the IP to that certificate accoring to Virustotal https://www.virustotal.com/#/ip-address/204.154.199.184 is resolving to microsoftapis(.)com – for sure nothing good.
Some other funny things where found by a quick look…
Hack me if you can
Hack me if you can
Happy Hacker fake CA
Happy Hacker Fake CA
This outlines the importance of:
Share the data (kudos FoxIT!)
Provide researchers access to data sets (thx to CIRCL and Virustotal!)
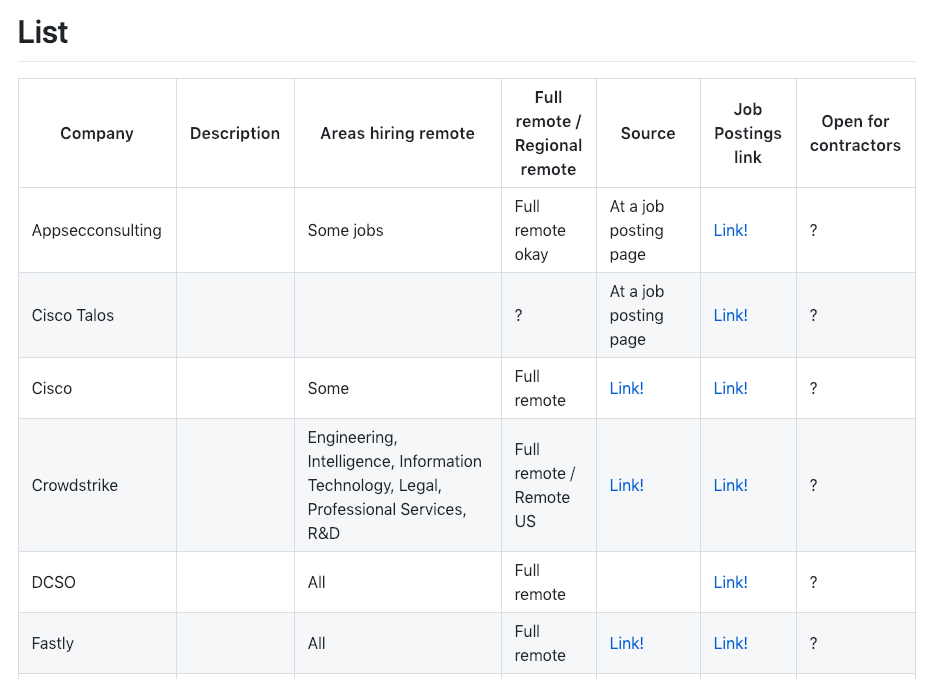
There are a whole bunch of articles outlining the talent gap in security related positions. More and more jobs require IT skills and IT systems are more and more integrated in all areas of our life with an dramatic increase of open positions in security and privacy.
People living in areas like SF / silicon valley, New York or Zurich can find easily new jobs within days, but those locations are also very expensive and some companies can not hire there.
There is a good opportunity to fight the talent gap: hiring remote
This post is not to outline the benefits of shortcomings of working / hiring remote but the fact that it is very hard for candidates to find companies welcoming remote security minded people.
On the other side, companies have a hard job, market themselves against the big brands to attract remote people.
That combined is the reason I created yet another list on github, called companies-hiring-security-remote. It is a curated list and open for issues / pull requests to act as a platform for job seeking people and companies to give them a little more visibility.
I really hope that this will help people and I am happy to receive feedback.
Investigation bad people might involve bitcoin, the blockchain technology is very popular among criminals, as it is easy to use and „untraceable“ [1]. E.g. in most ransomware cases like „Ryuk“ [2] the company Crowdstrike has listed several bitcoin wallets, that they attribute to the threat actor.
How can that information help your investigation / your intelligence gathering? IN certain ways, you could track your own wallets for transactions to these wallets. Another aspect, that this blogpost will cover on is the timeline aspect of it.
As bitcoin transactions make use of the blockchain, who is public by design, it is possible to:
tell, how many bitcoins a certain wallet currently holds
see transactions from the past
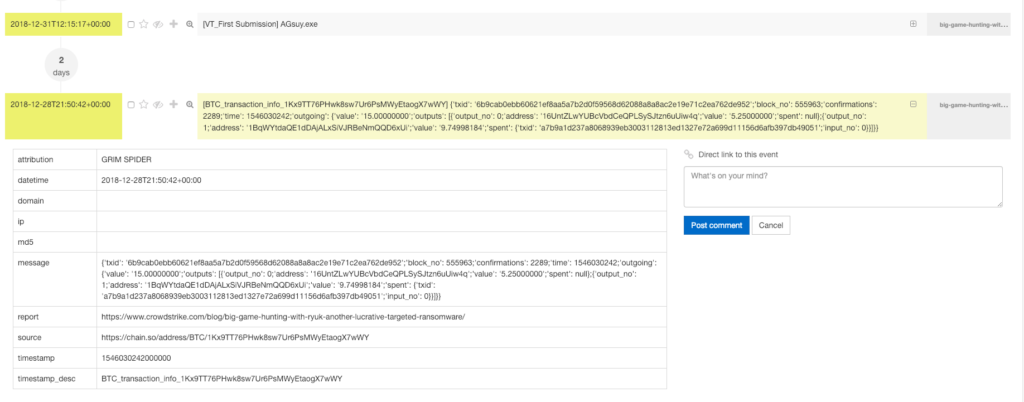
The second aspect is what I want to focus on, because if we have a look at the transactions, we might be able to identify the point in time a certain group was active and enhance our other DFIR activities enriched with that information. The transaction log is like your journal of your bank account, it tells basically who is transferring money to a wallet and where the bitcoins are transferred to.
In the example above, the bitcoin wallets we are interested in are (Source Crowdstrike Blog post):
BTC Address
Total Received
No Received
Total Value (USD)
12vsQry1XrPjPCaH8gWzDJeYT7dhTmpcjL
55.00
3
$221,685.46
1Kx9TT76PHwk8sw7Ur6PsMWyEtaogX7wWY
182.99
10
$734,601.91
1FtQnqvjxEK5GJD9PthHM4MtdmkAeTeoRt
48.250
4
$188,974.93
14aJo5L9PTZhv8XX6qRPncbTXecb8Qohqb
25.00
2
$113,342.70
1E4fQqzCvS8wgqy5T7n1DW8JMNMaUbeFAS
0.001
1
$6.47
1GXgngwDMSJZ1Vahmf6iexKVePPXsxGS6H
30.00
3
$132,654.91
1Cyh35KqhhDewmXy63yp9ZMqBnAWe4oJRr
0.00
0
$0.00
15LsUgfnuGc1PsHJPcfLQJEnHm2FnGAgYC
0.00
0
$0.00
1CbP3cgi1Bcjuz6g2Fwvk4tVhqohqAVpDQ
13.00
2
$82,917.49
1Jq3WwsaPA7LXwRNYsfySsd8aojdmkFnW
35.00
1
$221,979.83
129L4gRSYgVJTRCgbPDtvYPabnk2QnY9sq
0.00
0
$0.00
1ET85GTps8eFbgF1MvVhFVZQeNp2a6LeGw
3.325
1
$12,661.74
1FRNVupsCyTjUvF36GxHZrvLaPtY6hgkTm
38.99
3
$246,893.95
1CW4kTqeoedinSmZiPYH7kvn4qP3mDJQVa
24.077
2
$152,727.13
13rTF3AYsf8xEdafUMT5W1E5Ab2aqPhkPi
0.00
0
$0.00
17zTcgKhF8XkWvkD4Y1N8634Qw37KwYkZT
0.00
0
$0.00
14dpmsn9rmdcS4dKD4GeqY2dYY6pwu4nVV
0.00
0
$0.00
17v2cu8RDXhAxufQ1YKiauBq6GGAZzfnFw
0.00
0
$0.00
1KUbXkjDZL6HC3Er34HwJiQUAE9H81Wcsr
10.00
1
$63,358.27
12UbZzhJrdDvdyv9NdCox1Zj1FAQ5onwx3
0.00
0
$0.00
1NMgARKzfaDExDSEsNijeT3QWbvTF7FXxS
0.00
0
$0.00
19AE1YN6Jo8ognKdJQ3xeQQL1mSZyX16op
25.00
1
$164,774.21
1L9fYHJJxeLMD2yyhh1cMFU2EWF5ihgAmJ
40.035
4
$259,478.16
18eu6KrFgzv8yTMVvKJkRM3YBAyHLonk5G
30.00
1
$198,651.35
1C8n86EEttnDjNKM9Tjm7QNVgwGBncQhDs
30.0082
2
$194,113.76
12N7W9ycLhuck9Q2wT8E6BaN6XzZ4DMLau
0.00
0
$0.00
162DVnddxsbXeVgdCy66RxEPADPETBGVBR
0.00
0
$0.00
1ChnbV4Rt7nsb5acw5YfYyvBFDj1RXcVQu
28.00
2
$175,177.98
1K6MBjz79QqfLBN7XBnwxCJb8DYUmmDWAt
1.7
2
$12,455.95
1EoyVz2tbGXWL1sLZuCnSX72eR7Ju6qohH
0.00
0
$0.00
1NQ42zc51stA4WAVkUK8uqFAjo1DbWv4Kz
0.00
0
$0.00
15FC73BdkpDMUWmxo7e7gtLRtM8gQgXyb4
0.00
0
$0.00
14hVKm7Ft2rxDBFTNkkRC3kGstMGp2A4hk
10.00
2
$64,990.62
1CN2iQbBikFK9jM34Nb3WLx5DCenQLnbXp
15.00
1
$92,934.80
1LKULheYnNtJXgQNWMo24MeLrBBCouECH7
0.00
0
$0.00
15RLWdVnY5n1n7mTvU1zjg67wt86dhYqNj
50.41
3
$326,477.83
1KURvApbe1yC7qYxkkkvtdZ7hrNjdp18sQ
0.00
0
$0.00
1NuMXQMUxCngJ7MNQ276KdaXQgGjpjFPhK
10
1
$41,034.54
Source of transaction information
There is a whole bunch of public webpages who give transaction history for a given wallet, but as it should be an automated step, the goal is to have a page with an API, after some searching I found: https://chain.so/api .
Making the call
Doing the API call to get transaction information is pretty simple:
Which is exactly what we need, with some Python JSON parsing, it is easy to get the info we want – the code I am using is available on https://github.com/deralexxx/osint_to_timesketch
After that we have an CSV with the date, the transaction happened, the raw information from the API and some meta data, enough to bake into a timeline.
Automation
The script is already made to output CSV files ready for importing them into Timesketch, as I found it to be the ideal tool to work with data points related to timestamps. Importing the CSV is straight forward and explained in the official documentation page [3].
The timeline csv looks like the following:
CSV of BTC history
Making it pretty
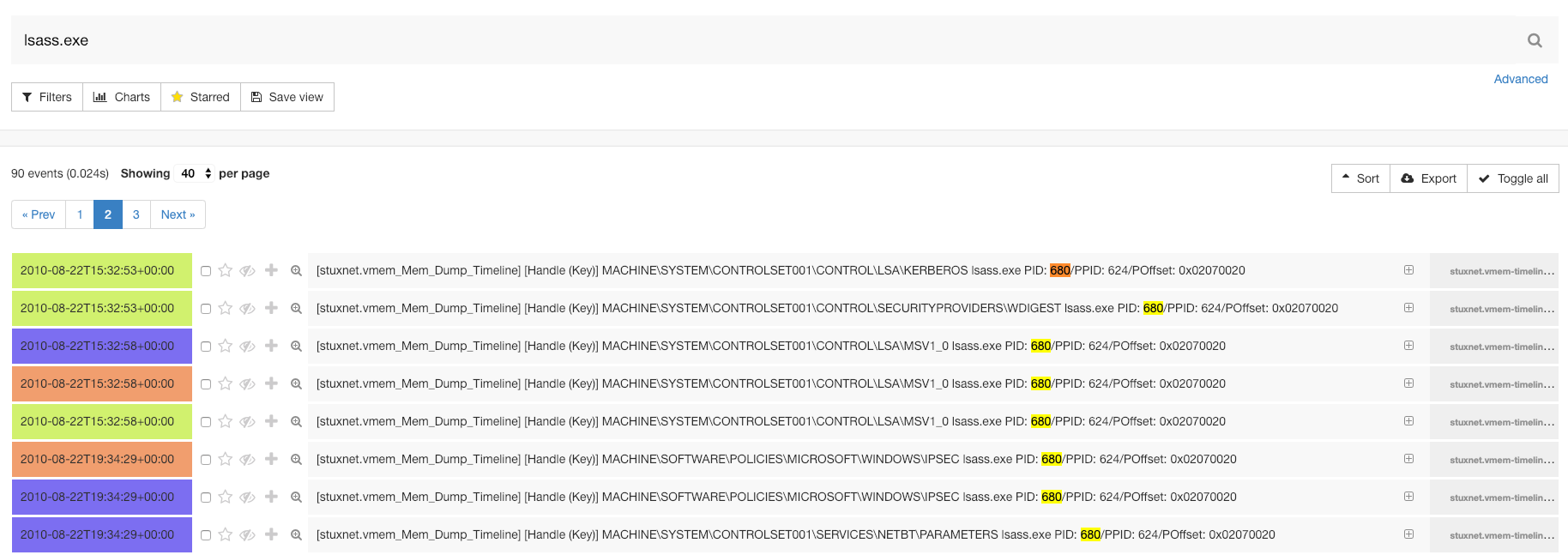
Importing it into Timesketch, the timeline looks very nice:
BTC transactions in Timesketch
Added Value
Now what is the added value for investigations? The above is another layer of data points /evidence. It can be used to weight limit findings in your organisation, e.g. you assume you are hit by a phishing campaign, if your phishing campaign was seen a lot earlier or a lot later than the transactions above display, it is unlikely you are hit by the same campaign. It can also be used to make a case against individuals if enriched by host forensics – your imagination is the limit.
End
I hope the article is helpful and the scripts can be used, let me know via comments within the blog, issues on github or twitter messages https://twitter.com/alexanderjaeger if you have any questions, improvements.
As you might know, I love to combine several OpenSource tools to get things done. One thing I wanted to play for some weeks is Autotimeliner by Andrea Fortuna.This tool is made to extract events from an Memory Image to combine it into a timeline. If you have a timeline, what comes next? Of course, putting it into Timesketch. So let’s give it a try.
We start with a memory dump from a Stuxnet infection from https://github.com/ganboing/malwarecookbook. Download the four files, extract them and you are good to go.
Prerequisites
Volatility
Installation is pretty easy, install Volatility either via pre-compiled binary or install it manually, see the Volatility installation wiki for further information.
A simple, intuitive web app for analysing and decoding data without having to deal with complex tools or programming languages. CyberChef encourages both technical and non-technical people to explore data formats, encryption and compression.
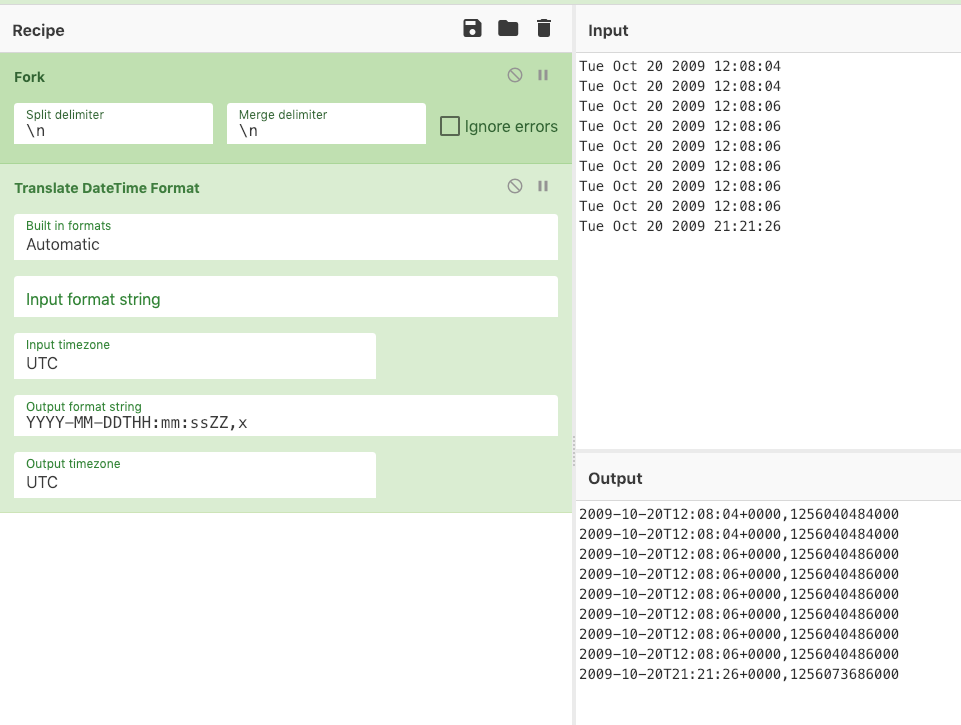
From the CSV that was generated, use your favourite tool to extract the first column of the csv which should look like that:
Date
Tue Oct 20 2009 12:08:04
Tue Oct 20 2009 12:08:04
Tue Oct 20 2009 12:08:06
Tue Oct 20 2009 12:08:06
Tue Oct 20 2009 12:08:06
Tue Oct 20 2009 12:08:06
Tue Oct 20 2009 12:08:06
Tue Oct 20 2009 12:08:06
Tue Oct 20 2009 21:21:26
Wed Oct 21 2009 00:02:28